主题
概念详解
建议先读 认识 SDD 了解核心理念,本页深入展开每个概念。
工作流全貌
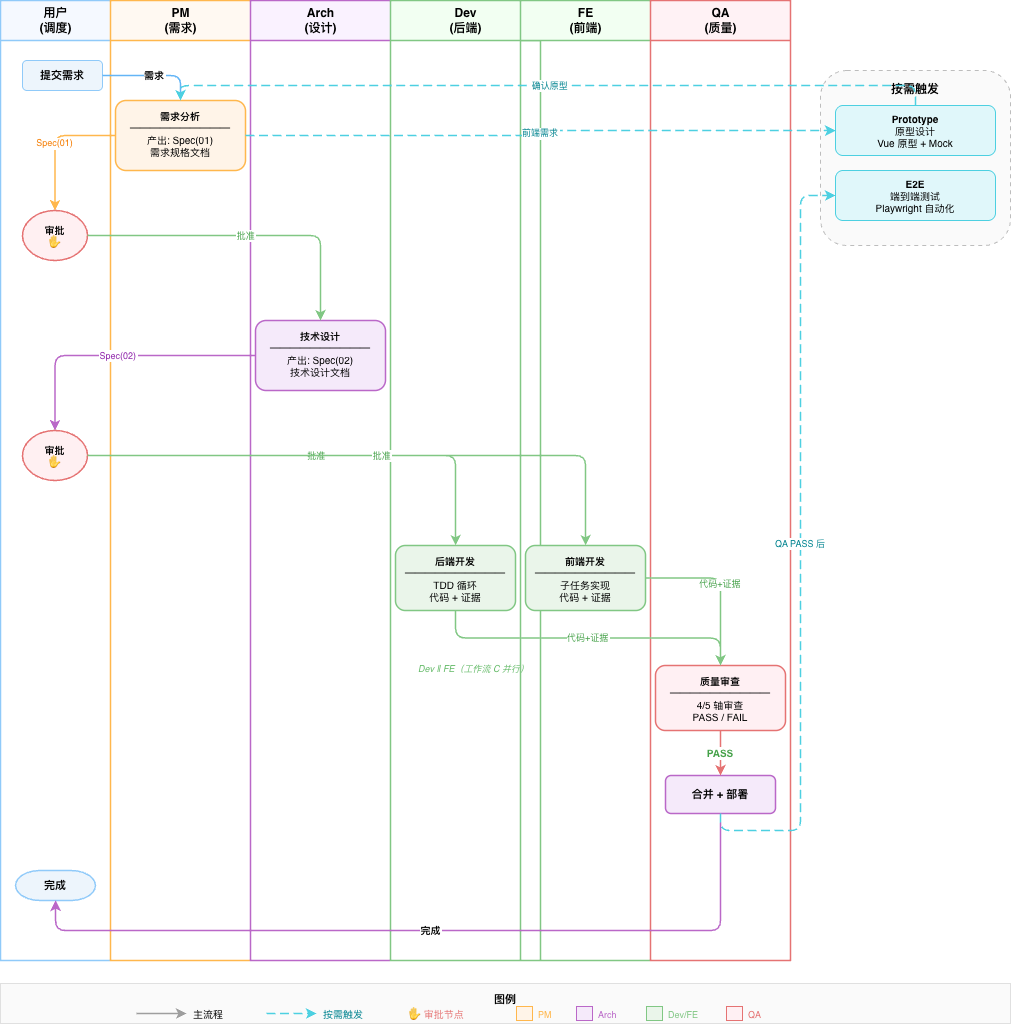
HCodeFlow 把 AI 编码过程拆成 6 个步骤,每个步骤都有明确的输入、输出和负责人:
需求 ──→ Intake(澄清) ──→ Plan(设计) ──→ Approval(审批) ──→ Execute(实现) ──→ Review(审查)
│
Merge(合并) ←──────────────────────────────────────────────┘| 阶段 | 做什么 | 谁来做 | 产出 | 人的参与 |
|---|---|---|---|---|
| Intake | 澄清需求:目标/边界/验收标准 | 你 + AI | 需求摘要 | 你回答三问 |
| Plan | 写需求文档 + 技术设计 | PM Agent + Architect Agent | Spec 01 + 02 | 你审批 |
| Approval | 人确认方案可以执行 | 你 | 审批决定 | 你拍板 |
| Execute | 写代码 + 写测试 | Dev Agent / FE Agent | 代码 + 03 文档 | 不需要 |
| Review | 审查代码质量和规范遵从 | QA Agent | PASS / FAIL | 你确认 |
| Merge | 合并代码到目标分支 | 你 | 合并提交 | 你决定 |
核心理念:每个阶段都是一次"信息传递",从人到 AI、从角色到角色,通过 Spec 文档实现确定性传递。
四种工作流模式
不是所有需求都需要走完整的 6 步。HCodeFlow 根据需求复杂度自动选择工作流:

| 模式 | 适用场景 | Spec 级别 | 流程 | 举例 |
|---|---|---|---|---|
| Q0 轻量 | 单文件改动、bug fix、配置调整 | 简要确认 | 你 → AI 直接改 | 改按钮颜色、修 typo |
| A 纯后端 | API / 数据库 / 后端逻辑 | 01 + 02(后端) | PM → Arch → Dev → QA | 新增 API 接口 |
| B 纯前端 | 页面 / 组件 / 交互 | 01 + 02(前端) | PM → Arch → FE → QA | 新增页面 |
| C 全栈 | 前后端联动(新增业务实体) | 01 + 02(全) | PM → Arch → Dev + FE 并行 → QA | 新增订单功能 |
AI 如何判断用哪个工作流?
你不需要记住判断逻辑,AI 会自动路由。 但了解它有助于你写出更好的需求描述。
七角色
HCodeFlow 定义了 7 个 AI Agent 角色,每个角色有明确的职责和边界:
| 角色 | 一句话职责 | 什么时候出场 |
|---|---|---|
| PM Agent | 把模糊需求变成结构化的需求文档 | 所有正式工作流 |
| Architect Agent | 设计技术方案(API/DB/前端架构) | 所有正式工作流 |
| Dev Agent | 写后端代码 | 工作流 A/C |
| FE Agent | 写前端代码 | 工作流 B/C |
| QA Agent | 独立审查代码质量 | 所有正式工作流 |
| Prototype Agent | 搭建前端原型 | 按需(需要快速验证 UI 时) |
| E2E Runner | 执行端到端测试 | 按需(需要自动化测试时) |
你只需要跟主对话交互,Agent 调度全自动。 你不会直接跟 PM Agent 或 Dev Agent 对话,AI 会在后台自动协调它们。
Spec 文档体系
Spec(Specification)是 SDD 的核心载体。每个 Feature 会生成一组文档,按编号排列:
.claude/specs/2026-04-27_14-30_user-search/
├── 01_requirement.md ← PM Agent 产出
├── 02_technical_design.md ← Architect Agent 产出
├── 03_impl_backend.md ← Dev Agent 产出(实现日志)
├── 03_impl_frontend.md ← FE Agent 产出(实现日志)
├── 04_test_plan.md ← QA Agent 产出
└── evidences/ ← 验证证据(截图、日志等)每个文档包含什么?
01 需求文档(PM 产出)— 用业务语言描述:
- 目标:要解决什么问题
- 功能点:具体做什么(字段级描述)
- 边界:什么不做
- 验收标准:怎么算完成
02 技术设计(Architect 产出)— 用技术语言描述:
- API 设计:端点、请求/响应格式
- 数据库改动:新增/修改的表和字段
- 前端改动:组件、路由、状态管理
- 测试场景:关键测试用例
- 风险点:可能的技术风险
03 实现日志(Dev/FE 产出)— 记录实现过程:
- 修改了哪些文件
- 关键实现决策
- 与 Spec 的对应关系
04 测试计划(QA 产出)— 验证代码质量:
- 测试矩阵(Spec 需求 → 测试用例)
- 边界条件覆盖
- 回归风险评估
确定性空间五要素
HCodeFlow 通过 5 类文件构建"确定性空间",让 AI 在明确的约束下工作:
| 要素 | 是什么 | 对应位置 | 解决什么问题 |
|---|---|---|---|
| Rules | 编码硬规则 | .claude/rules/ | 不用每次提醒"别用 var"、"SQL 不能拼接" |
| Skills | 领域知识库 | .claude/skills/ | 按需加载,避免 Context 爆炸 |
| Specs | Feature 全链路文档 | .claude/specs/ | 需求→设计→实现→验证的信息传递载体 |
| Agents | 角色定义 + 行为边界 | .claude/agents/ | 每个 Agent 知道自己该干什么、不该干什么 |
| Memory | 跨会话持久记忆 | .claude/project-memory/ | 项目知识不丢失,下次对话不用重新说 |
项目知识体系
确定性空间解决"AI 在什么约束下工作",但 AI 还需要理解你的项目:代码结构是什么样的?哪些经验值得复用?项目知识体系回答这些问题。
它包含两个互补的机制:
Domain Codemap ──→ "代码长什么样"(静态结构导航)
Knowledge Protocol ──→ "怎么做、为什么这么做"(动态经验管理)Domain Codemap — 代码地图
AI 的项目代码导航图,让 Agent 快速定位"代码在哪、怎么改"。
解决什么问题
新接触一个业务域时(无论 AI 还是人),最耗时的不是写代码,而是理解代码结构。Codemap 把"从入口到实现"的代码关系显式化,Agent 不用每次都盲目搜索。
长什么样
每个业务域一份 codemap,放在 .claude/codemap/domains/ 下:
.claude/codemap/domains/
├── user-management.md ← 用户管理域
├── order-processing.md ← 订单处理域
└── ... ← 按业务域拆分,每份控制在 200 行内每份 codemap 包含 9 个固定节:
| 节 | 内容 | 谁用 |
|---|---|---|
| 1. 功能边界 | 管什么 / 不管什么 | 所有角色 |
| 2. 入口总览 | Controller、Store、定时任务 | 所有角色 |
| 3. 主流程图 | 核心操作的调用链路 | Arch / Dev / FE |
| 4. 后端分层 | Controller → Service → Mapper 方法清单 | Arch / Dev |
| 5. 前端结构 | 页面 → Store → API 对应关系 | Arch / FE |
| 6. 关键数据结构 | Entity/VO 字段、枚举值、隐式映射 | Arch / Dev / FE |
| 7. 影响分析 | 本次 Feature 改动点(动态工作区) | Arch |
| 8. 风险热点 | 补偿逻辑、外部集成、非原子操作 | QA / Dev |
| 9. 切入点 | 关键文件的行号索引 | 所有角色 |
什么时候生成 / 更新
- 首次开发某业务域的 Feature 时,由 Architect Agent 自动生成
- Feature 完成后,Architect Agent 更新受影响的节(第 4/5/6/8 节),清空第 7 节
一个类比:Codemap = 你给新同事画的"代码地图"。第一次来的人照着地图就能找到入口、理解链路、知道风险在哪。AI Agent 也是"新来的",Codemap 让它不需要每次都从头读代码。
知识加载协议 — Knowledge Protocol
项目知识的分类、加载和沉淀规则,让 Agent 按需获取项目经验。
解决什么问题
Codemap 解决"代码结构"的问题,但项目还有很多"怎么做"的经验知识:"新增 API 要同时改这三个地方"、"导出功能有特殊权限校验"。知识加载协议定义了这些经验如何组织、Agent 如何按需加载、做完后如何沉淀新知识。
知识怎么分类
| 类型 | 放哪里 | 判断标准 | 举例 |
|---|---|---|---|
| Rules(硬约束) | .claude/rules/ | 违反了算 Bug 吗? | "SQL 禁止拼接" |
| Cookbook(实操指南) | .claude/context/cookbook-*.md | 有完整代码示例吗? | "新增 API 接口标准流程" |
| Pattern(设计模式) | .claude/context/pattern-*.md | 多场景复用、讲"为什么" | "前端 Store 拆分原则" |
Agent 怎么加载
Agent 进入子项目
↓
读取 knowledge-index.md(知识索引)
↓
匹配当前任务场景
├── 匹配到 → 加载对应的 cookbook/pattern
└── 没匹配 → 跳过,不阻塞工作流知识怎么沉淀
不预先批量生产,而是在实际开发中逐步积累,形成「加载 → 使用 → 沉淀」闭环:
| 谁沉淀 | 什么时候 | 沉淀成什么 |
|---|---|---|
| Dev / FE | 发现可复用的代码模式 | cookbook(实操指南) |
| Arch | 发现通用的架构方案 | pattern(设计模式) |
| QA | 发现反模式或常见问题 | rules(硬约束补充) |
一个类比:Knowledge Protocol = 团队的"经验文档系统"。Cookbook 是"怎么做菜"的菜谱,Pattern 是"为什么要这样调味"的设计原则。新同事按需查阅,做多了就自己贡献新菜谱。
Marker 机制
框架管理的文件都包含一个 Marker(标记行),用来区分"框架内容"和"项目自定义内容":

markdown
<!-- h-codeflow-framework:core v1.0.0-20260416 — DO NOT EDIT ABOVE THIS LINE, managed by upgrade.sh -->用"合同"来理解
把 Marker 想象成一份合同的分界线:
- Marker 上方 = 统一标准条款(所有项目一致,框架维护者更新)
- Marker 下方 = 项目附加条款(你的项目特有规则,永远不会被覆盖)
Marker 的关键特性
| 操作 | Marker 上方 | Marker 下方 |
|---|---|---|
| upgrade.sh 升级 | 会被覆盖为最新版 | 不变 |
| 你可以改吗? | 可以改,但下次升级会被覆盖 | 可以改,且永久保留 |
| 改了觉得好? | 用 harvest.sh 收割回框架 | 已经是你的了 |
upgrade.sh = 定期更新"统一标准"
框架 core/ ──→ upgrade.sh ──→ 项目 .claude/
只更新 marker 上方
marker 下方不受影响两层分离
HCodeFlow 的架构分为两层:
┌──────────────────────────────────────┐
│ 编排层(框架 core/) │
│ 通用的工作流定义,由 upgrade.sh 同步 │
│ 你不需要改这里 │
├──────────────────────────────────────┤
│ 执行层(项目 .claude/) │
│ 你的业务规则、编码规范、业务词典 │
│ marker 下方永远属于你 │
└──────────────────────────────────────┘- 编排层:
core/目录下的通用定义(Agent、Rules、Skills 模板等),所有下游项目共享 - 执行层:每个项目的
.claude/目录,包含项目特有的配置和知识
你每天做什么
用 HCodeFlow 的日常开发流程非常简单:
- 打开 Claude Code,描述需求
- 回答 Intake 三问(目标 / 边界 / 验收标准)
- 审批 PM 产出的需求文档(01)
- 审批 Arch 产出的技术设计(02)
- 等待 AI 自动完成开发 + QA
- 确认结果,合并代码
你的角色从"写代码"变成了"审批 Spec"。